一、初识算法
1、什么是算法
在数学和计算机科学领域,算法是一系列有限的严谨指令,通常用于解决一类特定问题或执行计算
In mathematics and computer science, an algorithm is a finite sequence of rigorous instructions, typically used to solve a class of specific problems or to perform a computation.
不正式的说,算法就是任何定义优良的计算过程:接收一些值作为输入,在有限的时间内,产生一些值作为输出。
Informally, an algorithm is any well-defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output in a finite amount of time.
2、什么是数据结构
在计算机科学领域,数据结构是一种数据组织、管理和存储格式,通常被选择用来高效访问数据
In computer science, a data structure is a data organization, management, and storage format that is usually chosen for efficient access to data
数据结构是一种存储和组织数据的方式,旨在便于访问和修改
A data structure is a way to store and organize data in order to facilitate access and modifications
可以说,程序 = 数据结构 + 算法,它们是每一位程序员的基本功,下来我们通过对一个非常著名的二分查找算法的讲解来认识一下算法
3、二分查找
主要参考文档 https://en.wikipedia.org/wiki/Binary_search_algorithm
二分查找算法也称折半查找,是一种非常高效的工作于有序数组的查找算法。后续的课程中还会学习更多的查找算法,但在此之前,不妨用它作为入门。
3.1、基础版
需求:在有序数组 A 内,查找值 target
- 如果找到返回索引
- 如果找不到返回 -1
算法描述:
前提:给定一个内含 n 个元素的有序数组 A,满足 $A_0 <= A_1 <= A_2 <= … <= A_n$,一个待查值 target
- 设置
i = 0, j = n-1 - 如果 i > j,结束查找,没找到
- 设置
m = floor[(i+j)/2],m 为中间索引,floor 是向下取整(<=(i+j)/2的最小整数) - 如果 $target \lt A_m$,设置 j = m – 1,跳到第 2 步
- 如果 $A_m \lt target$,设置 i = m + 1,跳到第 2 步
- 如果 $A_m = target$,结束查找,找到了
Java 实现:
/**
* 二分查找基础版
* @param a 待查找的升序数组
* @param target 待查找的目标值
* @return 找到则返回索引,找不到返回 -1
*/
public static int binarySearchBasic(int[] a, int target) {
// 设置指针和初值
int i = 0, j = a.length - 1;
while (i <= j) { // 范围内有东西
// int m = (i + j) / 2;
int m = (i + j) >>> 1;
if (target < a[m]) { // 目标在左边
j = m - 1;
} else if (a[m] < target) { // 目标在右边
i = m + 1;
} else { // 找到了
return m;
}
}
return -1;
}
- i、j 对应着搜索区间 [0, a.length-1](注意是闭合的区间),i <= j 意味着搜索区间内还有未比较的元素,i、j 指向的元素也可能是比较的目标
- 思考:如果不加
i == j行不行? - 回答:不行,因为这意味着当 i 与 j 相等时 i、j 指向的元素会漏过比较
- 思考:如果不加
- m 对应着中间位置,中间位置左边和右边的元素可能不相等(差一个),不会影响结果
- 如果某次未找到,那么缩小后的区间内不包含 m
问题 1:为什么是 i <= j 意味着区间内有未比较的元素,而不是 i < j ?
i == j意味着 i,j 它们指向的元素也会参与比较- i < j 只意味着 m 指向的元素参与比较
问题 2:
(i + j) / 2有没有问题?
- 有问题,当 i 和 j 都很大时,
(i + j) / 2的值可能会为负数,因为 Java 中默认是有符号数,i + j 的值的二进制表示最高位为 1 时则被视为负数,产生了正溢出。除 2 后仍是负数,而无符号右移操作能避免这种问题问题 3:都写成小于号有啥好处?
- 数组是升序的,写 < 跟数组升序排列的顺序一致,增强代码可读性
3.2、改动版
另一种写法
public static int binarySearchAlternative(int[] a, int target) {
int i = 0, j = a.length;
while (i < j) {
int m = (i + j) >>> 1;
if (target < a[m]) { // 在左边
j = m;
} else if (a[m] < target) { // 在右边
i = m + 1;
} else {
return m;
}
}
return -1;
}
- i,j 对应着搜索区间 [0, a.length)(注意是左闭右开的区间),i < j 意味着搜索区间内还有未比较的元素,j 指向的一定不是查找目标
- 思考:为啥这次不加
i == j的条件了? - 回答:这回 j 只是作为边界,指向的不是查找目标,如果还加
i == j条件,就意味着 j 指向的还会再次比较,找不到时,会死循环
- 思考:为啥这次不加
- 如果某次要缩小右边界,那么 j = m,因为此时的 m 已经不是查找目标了
4、衡量算法好坏
4.1、时间复杂度
下面的查找算法也能得出与之前二分查找一样的结果,那你能说出它差在哪里吗?
public static int search(int[] a, int target) {
for (int i = 0; i < a.length; i++) {
if (a[i] == target) {
return i;
}
}
return -1;
}
考虑最坏情况(没找到),例如 [1,2,3,4] 查找 5
int i = 0只执行 1 次i < a.length受数组元素个数 n 的影响,比较 n + 1 次i++受数组元素个数 n 的影响,自增 n 次a[i] == k受元素个数 n 的影响,比较 n 次return -1,执行 1 次
粗略认为每行代码执行时间是 t,假设 n = 4 那么
- 总执行时间是 $(1+4+1+4+4+1)*t = 15t$
- 可以推导出更一般地公式为 $T = (3*n+3)t$
如果套用二分查找算法,还是 [1,2,3,4] 查找 5
public static int binarySearch(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) { // 在左边
j = m - 1;
} else if (a[m] < target) { // 在右边
i = m + 1;
} else {
return m;
}
}
return -1;
}
int i = 0, j = a.length - 1各执行 1 次i <= j比较 $floor(\log_{2}(n)+1)$ 再加 1 次(i + j) >>> 1计算 $floor(\log_{2}(n)+1)$ 次- 接下来
if() else if() else会执行 $3* floor(\log_{2}(n)+1)$ 次,分别为- if 比较
- else if 比较
- else if 比较成立后的赋值语句
i = m + 1;
return -1,执行 1 次
结果:
- 总执行时间为 $(2 + (1+3) + 3 + 3 * 3 + 1)*t = 19t$
- 更一般地公式为 $(4 + 5 * floor(\log_{2}(n)+1))*t$
注意:
左侧未找到和右侧未找到结果不一样,这里不做分析,右侧没找到情况更差
两个算法比较,可以看到 $n$ 在较小的时候,二者花费的次数差不多
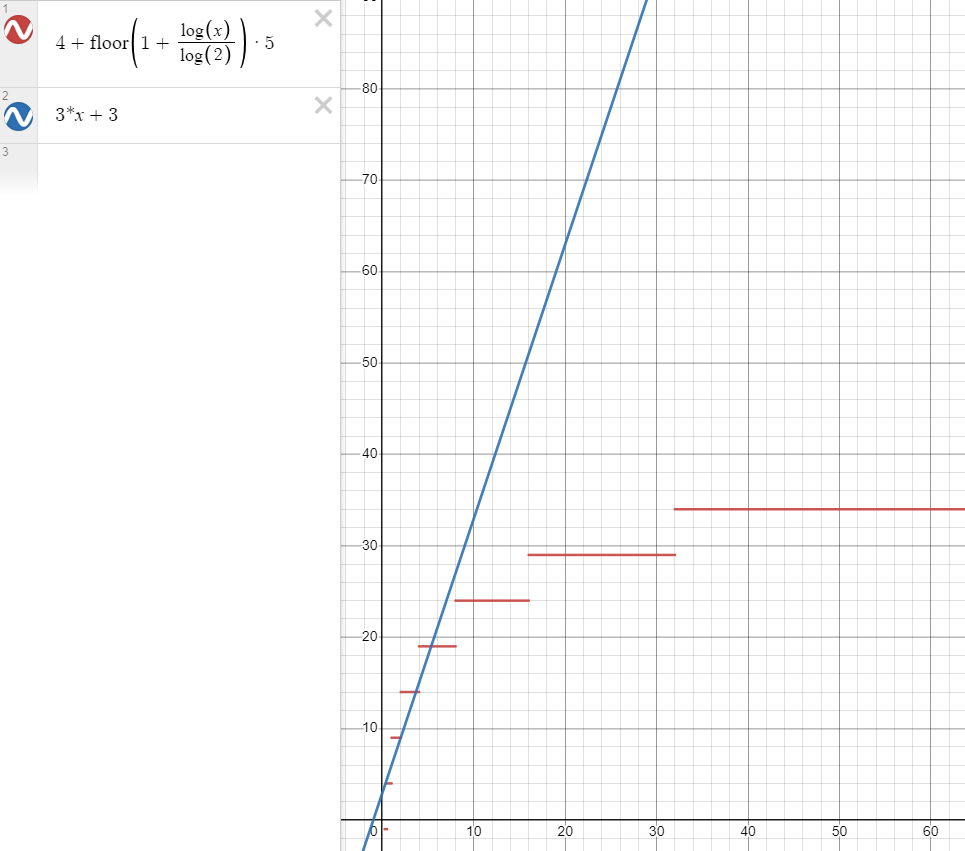
但随着 $n$ 越来越大,比如说 $n=1000$ 时,用二分查找算法(红色)也就是 $54t$,而蓝色算法则需要 $3003t$
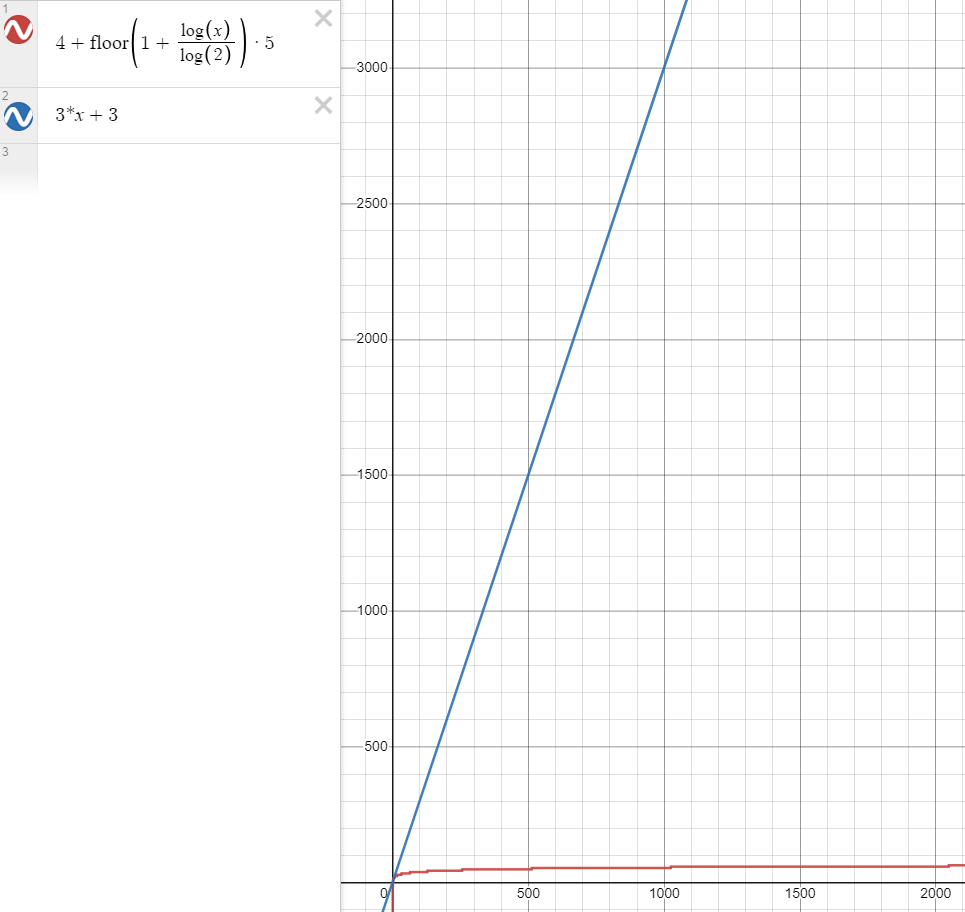
画图采用的是 Desmos | 图形计算器
计算机科学中,时间复杂度是用来衡量:一个算法的执行,随数据规模增大而增长的时间成本
- 它不依赖于环境因素
如何表示时间复杂度呢?
- 假设算法要处理的数据规模是 $n$,代码总的执行行数用函数 $f(n)$ 来表示,例如:
- 线性查找算法的函数 $f(n) = 3*n + 3$
- 二分查找算法的函数 $f(n) = (floor(log_2(n)) + 1) * 5 + 4$
- 为了对 $f(n)$ 进行化简,应当抓住主要矛盾,找到一个变化趋势与之相近的表示法
大 $O$ 表示法
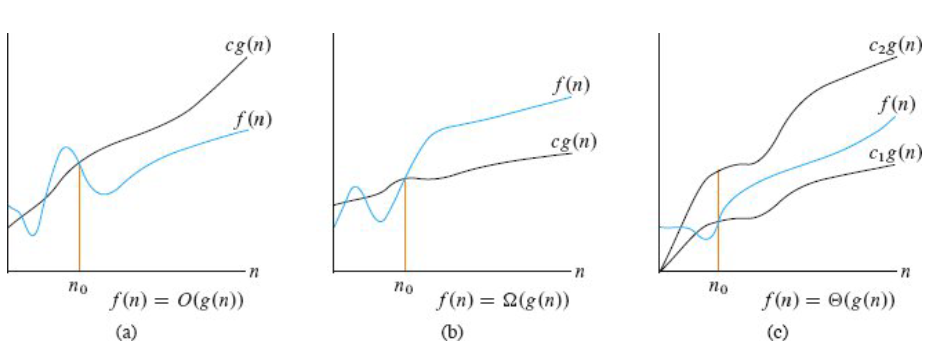
其中
- $c, c_1, c_2$ 都为一个常数
- $f(n)$ 是实际执行代码行数与 n 的函数
- $g(n)$ 是经过化简,变化趋势与 $f(n)$ 一致的 n 的函数
渐进上界
渐进上界(asymptotic upper bound):从某个常数 $n_0$ 开始,$c*g(n)$ 总是位于 $f(n)$ 上方,那么记作 $O(g(n))$
- 代表算法执行的最差情况
例 1:
- $f(n) = 3*n+3$
- $g(n) = n$
- 取 $c=4$,在 $n_0=3$ 之后,$g(n)$ 可以作为 $f(n)$ 的渐进上界,因此表示法写作 $O(n)$
例 2:
- $f(n) = 5*floor(log_2(n)) + 9$
- $g(n) = log_2(n)$
- $O(log_2(n))$
已知 $f(n)$ 来说,求 $g(n)$
- 表达式中相乘的常量,可以省略,如
- $f(n) = 100*n^2$ 中的 $100$
- 多项式中数量规模更小的项(低次项)可以省略,如
- $f(n)=n^2+n$ 中的 $n$
- $f(n) = n^3 + n^2$ 中的 $n^2$
- 不同底数的对数,渐进上界可以用一个对数函数 $\log n$ 表示
- 例如:$log_2(n)$ 可以替换为 $log_{10}(n)$,因为 $log_2(n) = \frac{log_{10}(n)}{log_{10}(2)}$,相乘的常量 $\frac{1}{log_{10}(2)}$ 可以省略
- 类似的,对数的常数次幂可省略
- 如:$log(n^c) = c * log(n)$
常见大 $O$ 表示法
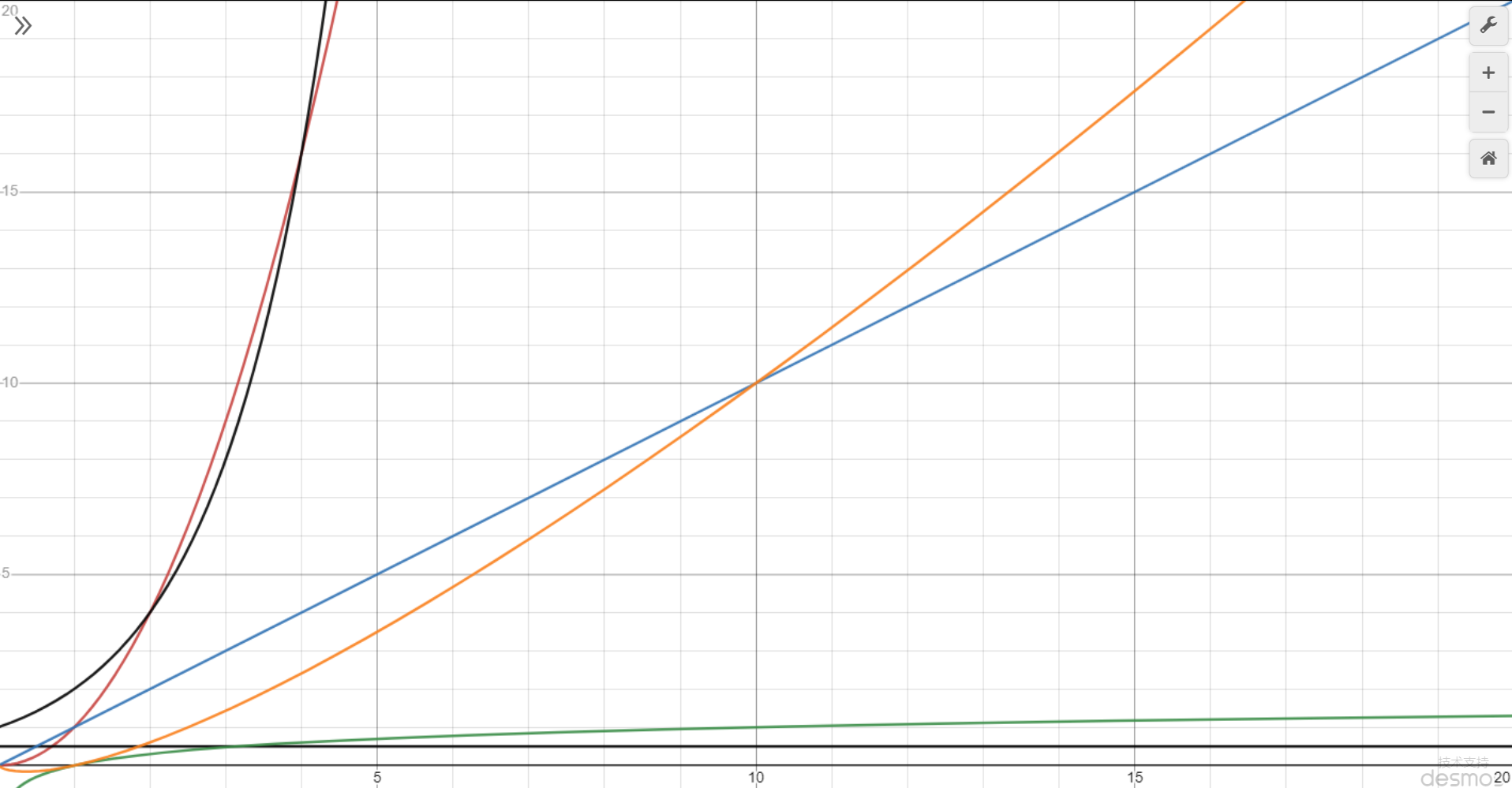
按时间复杂度从低到高:
- 黑色横线 $O(1)$,常量时间,意味着算法时间并不随数据规模而变化
- 绿色 $O(log(n))$,对数时间
- 蓝色 $O(n)$,线性时间,算法时间与数据规模成正比
- 橙色 $O(n*log(n))$,拟线性时间
- 红色 $O(n^2)$ 平方时间
- 黑色朝上 $O(2^n)$ 指数时间
- 没画出来的 $O(n!)$
渐进下界
渐进下界(asymptotic lower bound):从某个常数 $n_0$开始,$c*g(n)$ 总是位于 $f(n)$ 下方,那么记作 $\Omega(g(n))$
渐进紧界
渐进紧界(asymptotic tight bounds):从某个常数 $n_0$ 开始,$f(n)$ 总是在 $c_1 * g(n)$ 和 $c_2 * g(n)$ 之间,那么记作 $\Theta(g(n))$
4.2、空间复杂度
与时间复杂度类似,一般也使用大 $O$ 表示法来衡量:一个算法执行随数据规模增大,而增长的额外空间成本
public static int binarySearchBasic(int[] a, int target) {
int i = 0, j = a.length - 1; // 设置指针和初值
while (i <= j) { // i~j 范围内有东西
int m = (i + j) >>> 1;
if (target < a[m]) { // 目标在左边
j = m - 1;
} else if (a[m] < target) { // 目标在右边
i = m + 1;
} else { // 找到了
return m;
}
}
return -1;
}
二分查找性能
最后分析一下二分查找算法的性能
- 时间复杂度
- 最坏情况:$O(log n)$
最好情况:如果待查找元素恰好在数组中央,只需要循环一次 $O(1)$
空间复杂度
- 需要常数个指针 $i,j,m$,因此额外占用的空间是 $O(1)$
5、再看二分查找
5.1、平衡版
基础版中,假设已知循坏次数是 L 次,如果要查找的元素在最左边,则比较语句执行了 L 次。但如果要查找的元素在最右边,则比较次数为 2L 次。所以基础版的问题是左边找元素和右边找元素不是平衡的,向左找成本低,向右找成本高。
平衡版解决了这个问题:
public static int binarySearchBalance(int[] a, int target) {
int i = 0, j = a.length;
while (1 < j - i) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m;
} else {
i = m;
}
}
return (a[i] == target) ? i : -1;
}
思想:
- 左闭右开的区间,$i$ 指向的可能是目标,而 $j$ 指向的不可能是目标
- 不奢望循环内通过 $m$ 找出目标,缩小区间直至剩最后 1 个时(即只剩 $i$ 时)退出循环,剩下的这个可能就是要找的
- $j – i > 1$ 的含义是,在范围内待比较的元素个数 > 1
- 改变 $i$ 边界时,它指向的可能是目标,因此不能给 $i$ 赋值 $m+1$
- 三分支改为二分支,循环内的平均比较次数减少了
- 时间复杂度 $\Theta(log(n))$
5.2、JDK 中的二分查找
在 Arrays 类中,binarySearch0 方法源代码如下:
private static int binarySearch0(int[] a, int fromIndex, int toIndex, long key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
long midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
- 例如 $[1, 3, 5, 6]$ 要插入 2 那么就是找到一个位置,这个位置左侧元素都比它小
- 等循环结束,若没找到,low 左侧元素肯定都比 target 小,因此 low 即插入点
- 插入点取负是为了与找到情况区分
- 返回 $-(low+1)$ 而不是 $-low$ 是为了把索引 0 位置的插入点与找到的情况进行区分
5.3、Leftmost 与 Rightmost
有时我们希望返回的是最左侧的重复元素,如果用 Basic 二分查找的话,
- 对于数组 $[1, 2, 3, 4, 4, 5, 6, 7]$,查找元素 4,结果是索引 3
-
对于数组 $[1, 2, 4, 4, 4, 5, 6, 7]$,查找元素 4,结果也是索引 3,但并不是最左侧的元素
想要返回最左侧的重复元素,可将基础版的代码修改如下:
public static int binarySearchLeftmost1(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m; // 记录候选位置
j = m - 1; // 继续向左
}
}
return candidate;
}
如果希望返回的是最右侧元素:
public static int binarySearchRightmost1(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m; // 记录候选位置
i = m + 1; // 继续向右
}
}
return candidate;
}
5.4、Leftmost 与 Rightmost 改进版
对于 Leftmost 与 Rightmost,可以返回一个比 -1 更有用的值
Leftmost 改为:
public static int binarySearchLeftmost(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target <= a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i;
}
- Leftmost 返回值是大于等于目标值的最靠左索引位置,其另一层含义是:$\lt target$ 的元素个数
- 小于等于中间值,都要向左找
Rightmost 改为:
public static int binarySearchRightmost(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i - 1;
}
- Rightmost 的返回值是小于等于目标值的最靠右索引位置
- 大于等于中间值,都要向右找
改进后的 Leftmost 与 Rightmost 方法有许多应用,列举如下:
先看几个名词:
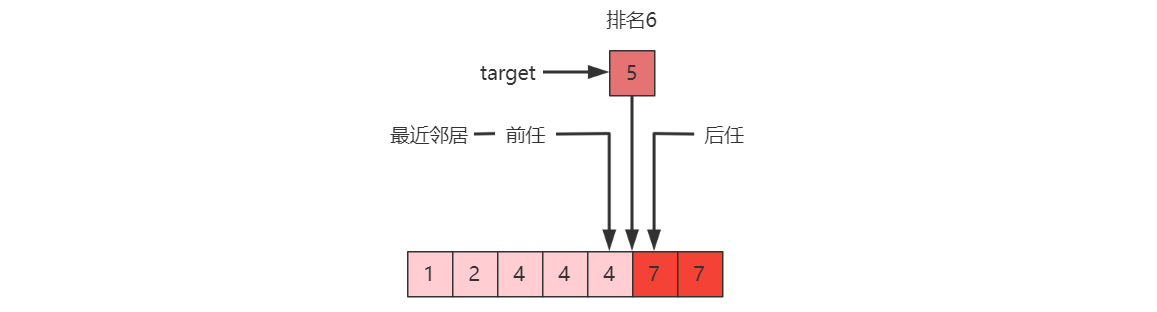
其中,最近邻居是指前任和后任中数值上最靠近目标值的,上图中 $5-4=1$,$7 – 5 = 2$,所以 4 是 target 的最近邻居
1、范围查询:
- 查询 $x \lt 4$,$0 … leftmost(4) – 1$
- 查询 $x \leq 4$,$0 … rightmost(4)$
- 查询 $x \gt 4$,$rightmost(4) + 1 … length-1$
- 查询 $x \geq 4$, $leftmost(4) … legth-1$
- 查询 $4 \leq x \leq 7$,$leftmost(4) … rightmost(7)$
- 查询 $4 \lt x \lt 7$,$rightmost(4)+1 … leftmost(7)-1$
2、求排名:$leftmost(target) + 1$
- $target$ 可以不存在,如:$leftmost(5)+1 = 6$
- $target$ 也可以存在,如:$leftmost(4)+1 = 3$
3、求前任(predecessor):$leftmost(target) – 1$
- $leftmost(3) – 1 = 1$,前任 $a_1 = 2$
- $leftmost(4) – 1 = 1$,前任 $a_1 = 2$
4、求后任(successor):$rightmost(target)+1$
- $rightmost(5) + 1 = 5$,后任 $a_5 = 7$
- $rightmost(4) + 1 = 5$,后任 $a_5 = 7$
5、求最近邻居:
- 前任和后任距离 target 更近者
6、习题
6.1、时间复杂度估算
用函数 $f(n)$ 表示算法效率与数据规模的关系,假设每次解决问题需要 1 微秒($10^{-6}$ 秒),进行估算:
- 如果 $f(n) = n^2$ 那么 1 秒能解决多少次问题?1 天呢?
- 如果 $f(n) = log_2(n)$ 那么 1 秒能解决多少次问题?1 天呢?
- 如果 $f(n) = n!$ 那么 1 秒能解决多少次问题?1 天呢?
参考解答
- 1秒 $\sqrt{10^6} = 1000$ 次,1 天 $\sqrt{10^6 * 3600 * 24} \approx 293938$ 次
- 1秒 $2^{1,000,000}$ 次,一天 $2^{86,400,000,000}$
- 推算如下
- $10! = 3,628,800$,1 秒能解决 $1,000,000$ 次,因此次数为 9 次
- $14!=87,178,291,200$,一天能解决 $86,400,000,000$ 次,因此次数为 13 次
6.2、耗时估算
一台机器对 200 个单词进行排序花了 200 秒(使用冒泡排序),那么花费 800 秒,大概可以对多少个单词进行排序
A. 400
B. 600
C. 800
D. 1600
答案:A
解释
冒泡排序时间复杂度是 $O(n^2)$,时间增长 4 倍,而因此能处理的数据量是原来的 $\sqrt{4} = 2$ 倍
6.3、搜索插入位置 — Leetcode 35
题目链接:https://leetcode.cn/problems/search-insert-position/description/
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
示例:
输入: nums = [1,3,5,6], target = 5
输出: 2
输入: nums = [1,3,5,6], target = 2
输出: 1
输入: nums = [1,3,5,6], target = 7
输出: 4
要点:理解谁代表插入位置
参考答案 1:用二分查找基础版代码改写,基础版中找到返回 m,没找到的话最终 i 代表插入点,这种类似于 JDK 中二分查找的实现,因此有
public int searchInsert(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
return m;
}
}
return i; // 原始 return -1
}
参考答案 2:用二分查找平衡版改写,平衡版中
- 如果
target == a[i]返回 i 表示找到 - 如果 target < a[i],例如 target = 2,a[i] = 3,这时就应该在 i 位置插入 2
- 如果 a[i] < target,例如 a[i] = 3,target = 4,这时就应该在 i + 1 位置插入 4
public static int searchInsert(int[] a, int target) {
int i = 0, j = a.length;
while (1 < j - i) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m;
} else {
i = m;
}
}
return (target <= a[i]) ? i : i + 1;
// 原始 (target == a[i]) ? i : -1;
}
参考答案 3:用 Leftmost 版本解,返回值即为插入位置(并能处理元素重复的情况)
public int searchInsert(int[] a, int target) {
int i = 0, j = a.length - 1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target <= a[m]) {
j = m - 1;
} else {
i = m + 1;
}
}
return i;
}
6.4、搜索开始结束位置 — Leetcode 34
题目链接:https://leetcode.cn/problems/find-first-and-last-position-of-element-in-sorted-array/description/
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题
示例
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
输入:nums = [], target = 0
输出:[-1,-1]
参考答案
public static int[] searchRange(int[] nums, int target) {
int x = leftmost(nums, target);
if(x == -1) {
return new int[] {-1, -1};
} else {
return new int[] {x, rightmost(nums, target)};
}
}
private static int leftmost(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m;
j = m - 1;
}
}
return candidate;
}
private static int rightmost(int[] a, int target) {
int i = 0, j = a.length - 1;
int candidate = -1;
while (i <= j) {
int m = (i + j) >>> 1;
if (target < a[m]) {
j = m - 1;
} else if (a[m] < target) {
i = m + 1;
} else {
candidate = m;
i = m + 1;
}
}
return candidate;
}